Web Page Scraping Agent
Overview
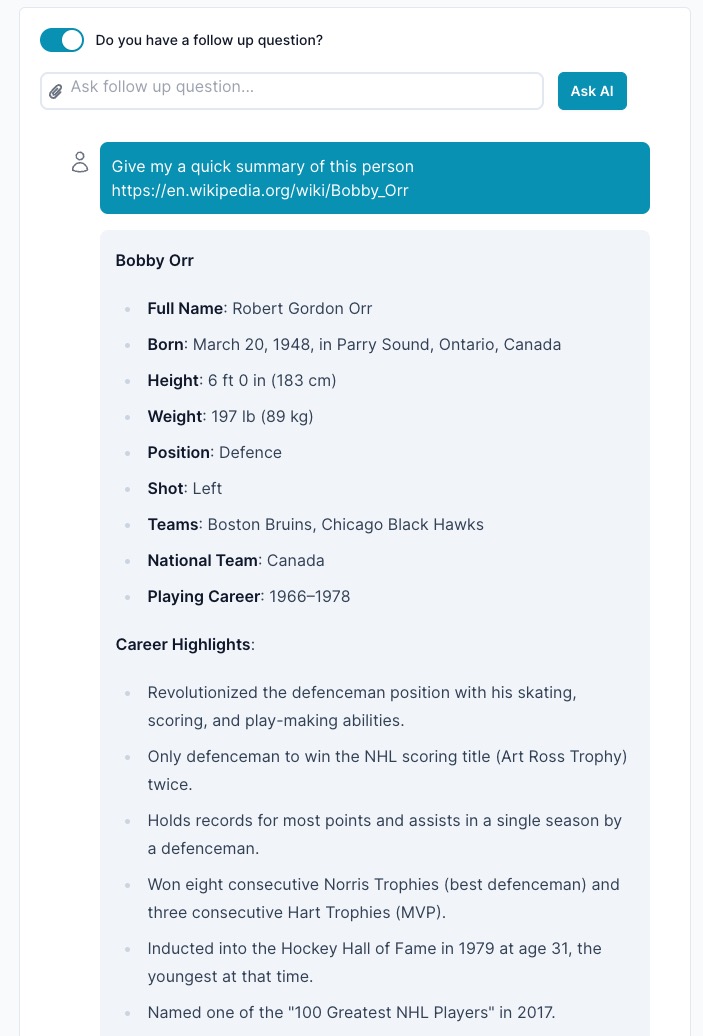
The Web Page Scraping Agent is an out-of-the-box Agent within the ai12z Copilot suite that allows you to retrieve and ingest the content from any HTML webpage by providing its URL. This agent enables the Large Language Model (LLM) reasoning engine to access and utilize up-to-date information from the web within your Copilot discussions or applications. By seamlessly integrating web content retrieval, this agent enhances the capabilities of your projects without requiring any customization, and it operates at a minimal cost—a fraction of a penny per use.
Key Features
- Content Retrieval: Extracts the textual content from any given webpage URL.
- LLM Integration: Allows the LLM reasoning engine to ingest and reference web content during Copilot discussions.
- Automatic HTML Parsing: Handles different website structures and formats to provide clean and usable content.
- Adaptive Scraping Modes: Utilizes different scraping methods to handle sites with advanced loading techniques.
- Easy Integration: As an out-of-the-box agent, it requires no customization and integrates seamlessly with your applications.
- Cost-Effective: Operates at a minimal cost, making it an economical choice for incorporating web content into your projects.
Purpose
The agent is designed to:
- Enhance Information Access: Provide real-time access to web content, allowing the LLM to reference up-to-date information during interactions.
- Simplify Web Content Retrieval: Eliminate the need for manual web scraping or integration of complex scraping libraries.
- Improve User Experience: Enable richer, more informed discussions and functionalities within your applications by incorporating external web content.
- Save Time: Automate the process of fetching and parsing web content, allowing you to focus on core application development.
How It Works
- Input Parameter: You provide the URL of the webpage you wish to scrape via the
urlparameter. - Content Retrieval: The agent attempts to retrieve the raw HTML content from the specified URL.
- Adaptive Scraping Modes: Depending on the website's structure and loading mechanisms, the agent may use different scraping modes (e.g., synchronous, asynchronous, advanced crawling) to obtain the content.
- Content Filtering: The raw HTML is parsed and filtered to extract clean textual content, removing unnecessary HTML tags, scripts, and styles.
- Output Delivery: Returns the extracted content as a plain text string, ready for use by the LLM reasoning engine or your application.
Integration with LLM Reasoning Engine
- Dynamic Content Ingestion: When the LLM needs to refer to a specific webpage, it can call this agent to ingest the content in real-time.
- Enhanced Discussions: The ingested content can be used within Copilot discussions to provide accurate and up-to-date information.
- Parallel Processing: The agent can be called multiple times to ingest content from different URLs, allowing the LLM to analyze and compare information from various sources.
Parameters
When invoking the Web Page Scraping Agent, you can specify the following parameter:
- url (string, required): The URL of the webpage to scrape content from. For example,
"https://www.example.com".
Enabling the Agent
To enable the Web Page Scraping Agent in your ai12z Copilot:
- Access the Agent Settings: Log in to your ai12z Copilot dashboard and navigate to the Agents section.
- Locate the Agent: Find the Web Page Scraping agent in the list of available agents.
- Enable the Agent: Click on the agent and select Enable to activate it for your projects.
- Set Parameters: When using the agent, specify the
urlparameter as needed for your application.
Usage Example
Ingesting Web Page Content
{
"function": "web_scrape",
"parameters": {
"url": "https://www.example.com/articles/latest-news"
}
}
In this example, the agent will:
- Retrieve the content from the specified article on "https://www.example.com".
- Return the extracted textual content as a string.
Output Example
{
"result": "Today, we are excited to announce the launch of our new product..."
}
Using with LLM Reasoning Engine
- Scenario: During a Copilot discussion, a user asks about the latest news on a specific topic.
- Process:
- The LLM identifies the need to reference up-to-date information from a specific webpage.
- It calls the Web Page Scraping Agent with the URL of the webpage containing the latest news.
- The agent retrieves and returns the content.
- The LLM incorporates this content into the discussion, providing an informed and accurate response.
Benefits
- Real-Time Information: Access the most recent content from the web, ensuring that the LLM's responses are based on current data.
- Improved Accuracy: By ingesting actual webpage content, the LLM can provide more precise and relevant information.
- Enhanced User Experience: Users receive comprehensive answers that can reference external sources seamlessly.
- Time Savings: Automates the content retrieval process, eliminating the need for manual intervention or additional development work.
Cost
Using the Web Page Scraping Agent is highly cost-effective. Each invocation incurs a minimal charge—a fraction of a penny—making it an affordable option for frequent use without significantly impacting your budget.
Limitations
- Content Restrictions: Some websites may have measures in place to prevent scraping or may serve content dynamically in ways that are difficult to scrape.
- Respect for Terms of Service: Ensure that scraping a website does not violate its terms of service or any applicable laws.
- No Media Retrieval: The agent focuses on extracting textual content and does not retrieve images, videos, or other media types.
- Content Quality: The quality of the extracted content may vary depending on the website's structure and may sometimes include unwanted text.
- Timeouts and Errors: Network issues or website restrictions may cause timeouts or errors during content retrieval.
Best Practices
- Verify Permissions: Before scraping a website, ensure you have the right to do so and that it complies with the website's terms of service.
- Use Responsibly: Avoid overloading websites with excessive scraping requests.
- Error Handling: Implement error handling in your application to manage cases where content cannot be retrieved.
- Content Filtering: Post-process the retrieved content if necessary to fit your application's needs.
Support
If you need assistance or have questions about the agent:
- Documentation: Refer to the ai12z Copilot documentation for more detailed information.
- Contact Us: Reach out to our support team at support@ai12z.com for personalized help.
By enabling the Web Page Scraping Agent, you empower your applications and the LLM reasoning engine to access and utilize real-time web content, enhancing interactions and providing users with accurate and relevant information—all with minimal effort and cost.