Image AI
Overview
Image AI is an advanced feature designed to enhance the capability of Large Language Models (LLMs) by integrating visual context into text-based processing. With Image AI, users can obtain image recommendations that are relevant to the LLM's textual response, providing a multimodal experience. This document outlines how to utilize the Image AI feature to match images with text-based answers and configure image processing settings.
Use Case
Image AI is particularly useful when a user requires a visual representation or confirmation of concepts discussed within the LLM's answers. For example, if the LLM describes a historical event, Image AI can provide relevant images to give a visual context to the description.
How It Works
The Image AI system operates through a sophisticated two-phase process:
Content Ingestion Phase
During the ingestion process of web pages and PDF documents, the system:
-
Page Context Tracking: Maintains detailed records of which page each image was found on, preserving the contextual relationship between images and their source content.
-
Enhanced Alt Text Generation: Combines multiple data sources to create comprehensive image descriptions:
- Original image alt text (if available)
- Page context and surrounding content
- Vision AI analysis of the actual image content
- This multi-layered approach ensures rich, contextually relevant image descriptions
Image Matching Phase
When a user query generates an LLM response:
-
Source Page Identification: The system identifies which specific pages contributed to generating the answer.
-
Context-Limited Matching: Image matching is intelligently limited to only those images found on the pages that were used to construct the response, ensuring contextual relevance.
-
Best Match Selection: From this filtered set of contextually relevant images, the system selects the most appropriate image based on the enhanced alt text and content analysis.
JSON-LD Structured Data Integration
ai12z leverages JSON-LD (JavaScript Object Notation for Linked Data) when available on web pages to significantly enhance content understanding and image context. JSON-LD provides structured, machine-readable data that offers superior context compared to traditional HTML parsing.
Benefits of JSON-LD Processing
When JSON-LD structured data is present on a page, ai12z can:
-
Enhanced Context Understanding: JSON-LD provides explicit semantic relationships between content elements, including images, allowing the LLM to understand the precise context and meaning of visual content.
-
Improved Image Association: Structured data clearly defines how images relate to specific content sections, products, articles, or concepts, enabling more accurate image-to-content matching.
-
Rich Metadata Extraction: JSON-LD often contains detailed metadata about images, including descriptions, captions, subject matter, and contextual relationships that may not be available in standard HTML.
-
Content Hierarchy Understanding: The structured nature of JSON-LD helps the system understand content relationships and hierarchies, improving both text comprehension and image relevance scoring.
Implementation Impact
Pages with well-implemented JSON-LD structured data will experience:
- More accurate image matching results
- Better contextual understanding of visual content
- Improved relevance of image recommendations
- Enhanced semantic understanding of page content
For optimal results, ensure your web pages include comprehensive JSON-LD structured data that describes both textual content and associated images.
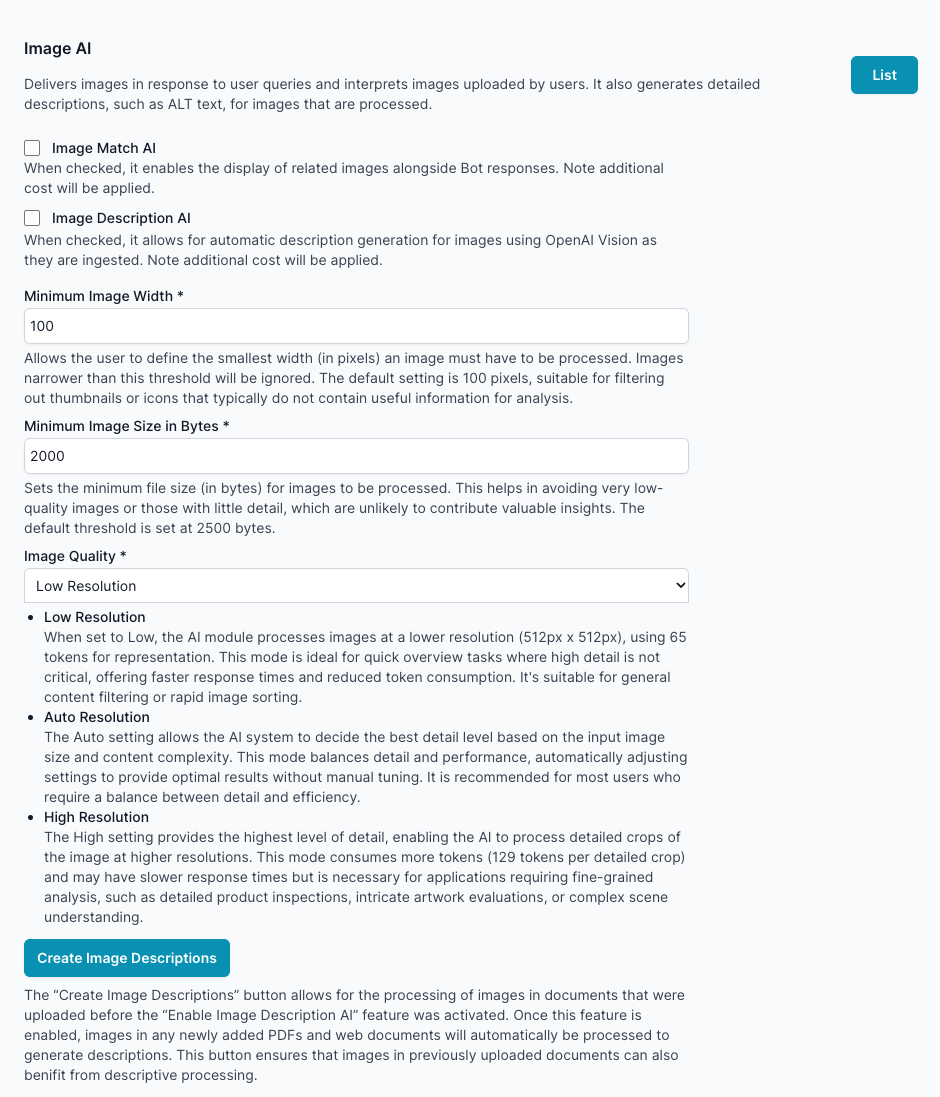
Configuration Options
-
Image Match AI:
- When checked, it enables the display of related images alongside Bot responses. Note additional cost will be applied.
-
Image Description AI:
- When checked, it allows for automatic description generation for images using OpenAI Vision as they are ingested. Note additional cost will be applied.
-
Minimum Image Width *:
- Allows the user to define the smallest width (in pixels) an image must have to be processed. Images narrower than this threshold will be ignored. The default setting is 100 pixels, suitable for filtering out thumbnails or icons that typically do not contain useful information for analysis.
-
Minimum Image Size in Bytes *:
- Sets the minimum file size (in bytes) for images to be processed. This helps in avoiding very low-quality images or those with little detail, which are unlikely to contribute valuable insights. The default threshold is set at 2500 bytes.
-
Image Quality *:
- Low Resolution: When set to AI module processes images at a lower resolution (512px x 512px), using 65 tokens for representation. This mode is ideal for quick overview tasks where high detail is not critical, offering faster response times and reduced token consumption. It's suitable for general content filtering or rapid image sorting.
- Auto Resolution: The Auto setting allows the AI system to decide the best detail level based on the input image size and content complexity. This mode balances detail and performance, automatically adjusting settings to provide optimal results without manual tuning. It is recommended for most users who require a balance between detail and efficiency.
- High Resolution: The High setting provides the highest level of detail, enabling the AI to process detailed crops of the image at higher resolutions. This mode consumes more tokens (129 tokens per detailed crop) and may have slower response times but is necessary for applications requiring fine-grained analysis, such as detailed product inspections, intricate artwork evaluations, or complex scene understanding.
-
Create Image Descriptions:
- The "Create Image Descriptions" button allows for the processing of images in documents that were uploaded before the "Enable Image Description" feature was activated. Once this feature is enabled, images in any newly added PDFs and web documents will automatically be processed to generate descriptions. This button ensures that images in previously uploaded documents can also benefit from descriptive processing.
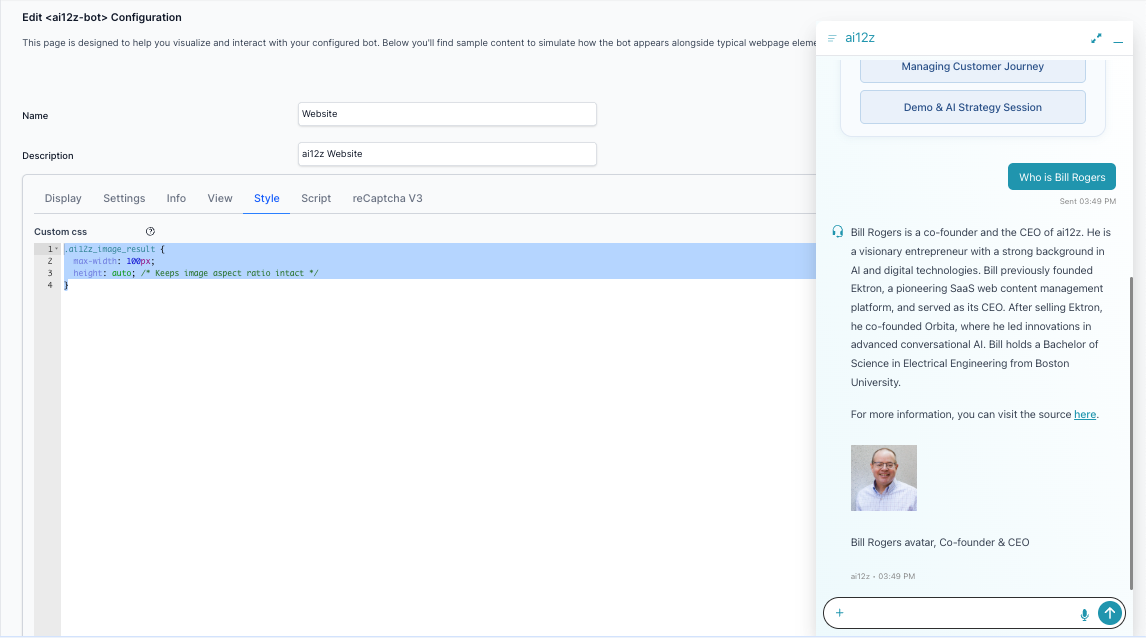
Image Display Control
You can control the max width or height of an image by using CSS:
.ai12z_image_result {
max-width: 230px;
height: auto; /* Keeps image aspect ratio intact */
}
The job will only process images not previously processed.