AI Workflow
ReAct Agentic Architecture, Tools, and RAG
A Modern Approach: ReAct – Reasoning, Action, and Real Results
The ai12z platform is built on a next-generation ReAct agentic workflow—centered on a powerful Reasoning Engine that does more than just answer questions (which is what the RAG does). It plans, takes action, and orchestrates the entire customer journey, drawing from your content, your systems, and real-time context.
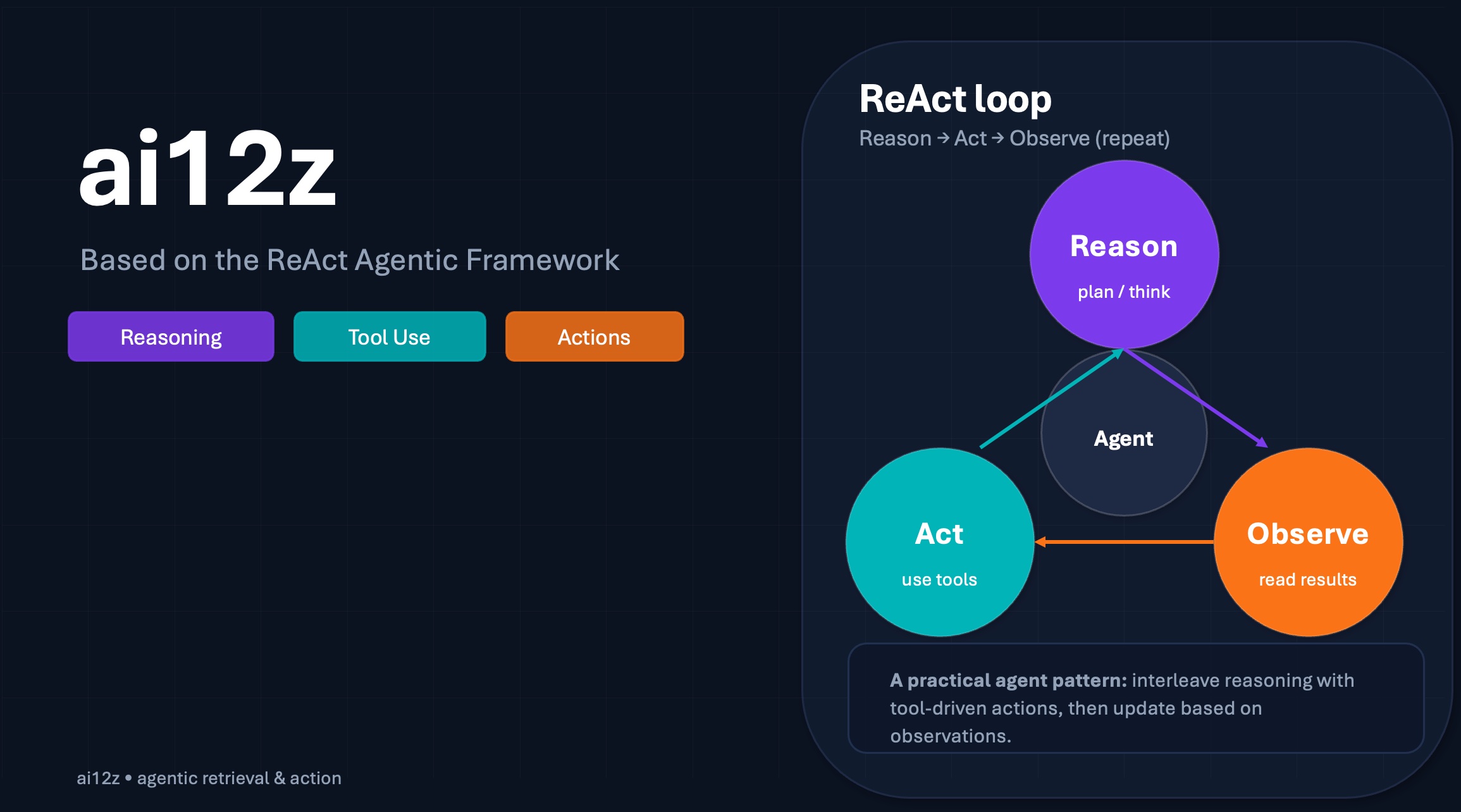
ai12z is built on the ReAct agentic workflow architecture, centered on a Reasoning Engine LLM augmented by tools (integrations) and RAG, which the ReAct LLM can invoke as a tool. ReAct stands for Reasoning and Action.
In this framework, the Reasoning Engine is guided by:
- The ReAct system prompt
- A list of available tools (integrations), including Answer AI (RAG) and Forms
- The complete conversation history
- Additional bot context (Attributes - GEO, page url, title, time and custom attributes)
- Overall goals and constraints
When a user asks a question, the ReAct LLM uses these inputs to build a step-by-step plan to achieve the goal. That plan can include calling one or more integrations or forms in a specific sequence, asking follow-up or clarifying questions, and adapting in real time as new information appears. When answering a question it can do more than just answer the question it can insert calls to actions, to achieve goals.
Because the model knows which integrations and forms are enabled, it can decide the best execution path and perform multiple planning cycles—refining or expanding the plan until the objective is completed.
ReAct Agentic Workflow Video
Integrations: Connecting Content, Data, and Actions
ai12z brings your ecosystem to life—connecting with CMS, CRM, DXP, inventory, scheduling, and virtually any third-party service via:
- MCP Protocol (Model Context Protocol), a standardized way for AI applications to interact with external tools and services through seamless two-way communication
- GraphQL & REST APIs
- Out-of-the-box connectors for Email, SMS, Google Maps, Stock, and more
- Answer AI (RAG) used when retrieval is needed, while ReAct determines when action integrations should be called
Whether you need real-time Shopify MCP queries, specialized ticketing integrations like Tessitura, or custom internal microservices, integrations transform your agent into an extension of your digital operations.
Unlike solutions that rely only on RAG, ai12z uses integrations for action-oriented tasks. Your copilot can answer questions and execute real operations—such as managing reservations, processing transactions, and updating inventory.
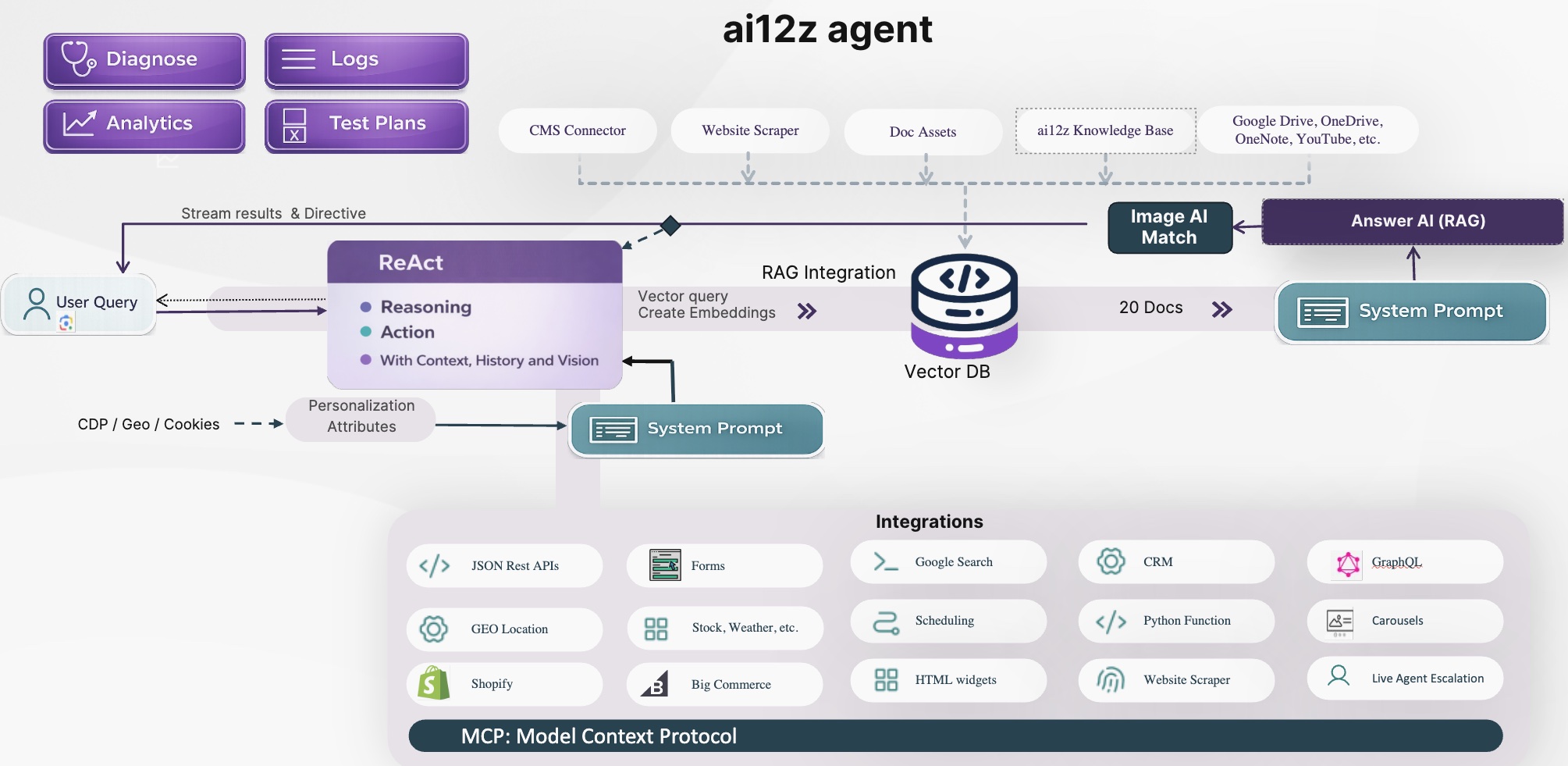
How RAG (Retrieval-Augmented Generation) works, and how a ReAct-style LLM uses conversation history to create the best possible vector search query.
Everything starts with the user’s message. For example: “How can I cancel my registration?” In real conversations, users ask follow-up questions such as “Can I cancel it?” or “What do I need to do next?” Those follow-ups only make sense when history is included.
This is where ReAct comes in:
- Reason: Understand true intent using the latest question plus prior conversation context
- Act: Rewrite the user request into a clean, high-quality vector query for retrieval
Instead of sending the raw user text directly to search, the system creates a context-aware vector query. For example, “Can I cancel it?” can become:
“How to cancel my registration, required steps, rules, and any deadlines.”
That rewritten query is then converted into an embedding (a numeric vector representation of meaning). Similar meanings are placed close together in semantic space.
The embedding is used to query the Vector Database index, which returns the top matching document chunks. This is Top-K retrieval (for example, K = 20), meaning the system returns the 20 most relevant chunks.
Each result includes chunk text and metadata such as page title, source URL, tags, and sometimes image references—making responses traceable and citable.
Finally, those Top-K chunks are passed into the Answer AI prompt. The model then generates a grounded response from retrieved content, reducing hallucinations and improving answer quality.
Big idea: ReAct improves retrieval by creating better vector queries from context and history. Better retrieval leads to better answers.
That is RAG in practice: retrieve the right knowledge first, then generate the answer using that knowledge.
Why ReAct and ai12z Beat Traditional Bot Frameworks
- Traditional bots rely on scripts and intent trees: rigid, high-maintenance, and easily outgrown.
- ai12z Agents are adaptive: using live context, continuous learning, and dynamic integration to deliver relevant, brand-safe answers—every time.
Key Differences:
- Adaptive, real-time conversations: Not tied to scripts, responds naturally and intelligently
- Integrated with all your content: No manual retraining for new info
- Seamless actions: Can complete tasks, not just answer
- Low-code, fast deployment: Business users and devs can launch and optimize in days
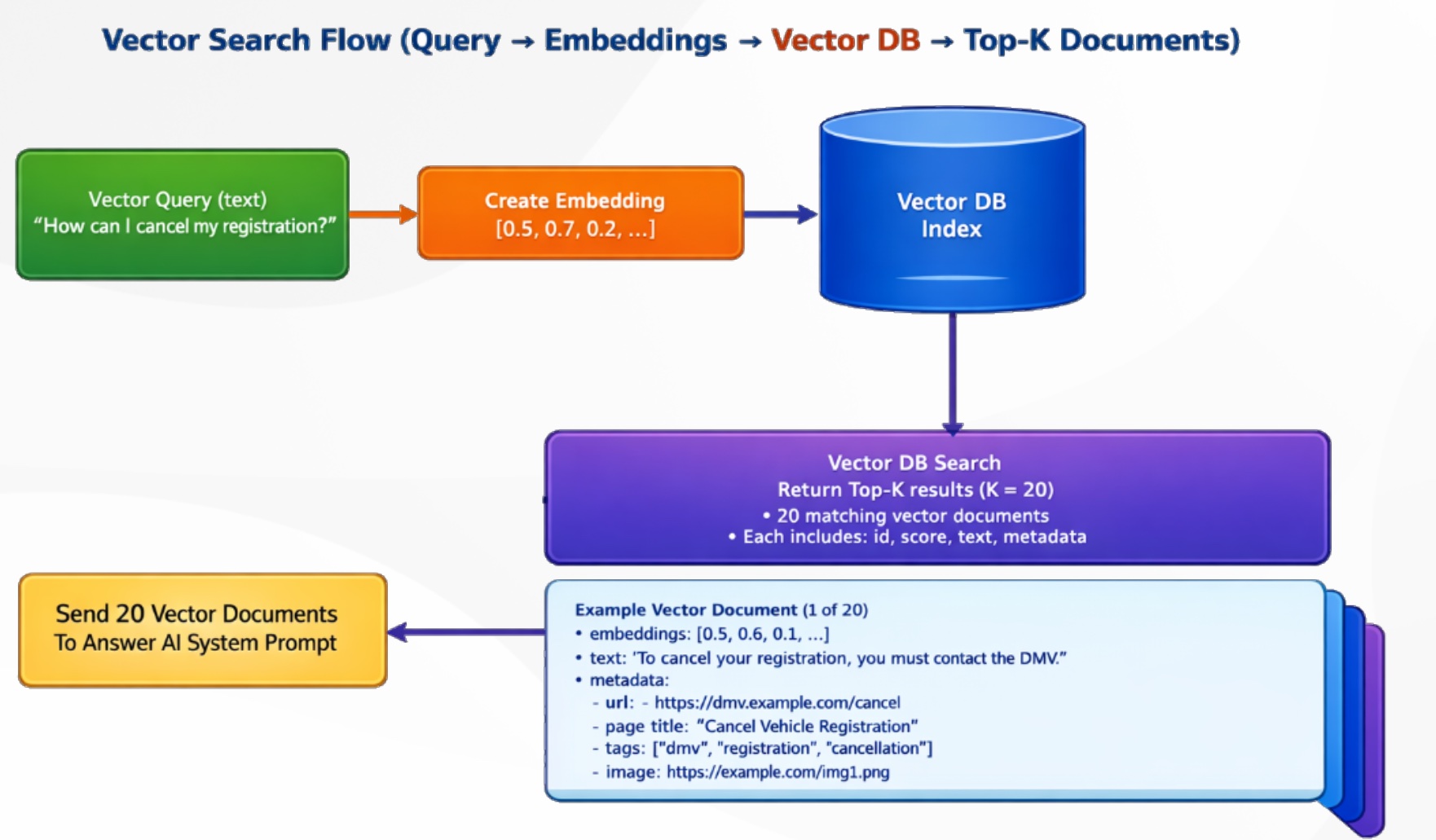
Deep Dive: How it Works
-
User Input: Users ask a question (text, voice, or image). The system can process text, understand uploaded images, and personalize responses using real-time context (location, language, etc).
-
Planning & Orchestration: The Reasoning Engine reviews available tools, integrations, and forms, and creates a step-by-step plan—possibly involving multiple agents (including RAG), API calls, and custom business logic.
-
Search & Retrieval: For knowledge-based questions, the system queries the Vector Database (storing text, embeddings, and metadata) to retrieve and rank the most relevant info.
Inside the Vector DB:
- Embeddings: Numeric vector representations for rapid semantic search
- Text: Source snippets
- Metadata: URL, page title, tags, images, and more
-
Answer Generation: The results from RAG and other integrations are used to build a final system prompt, which the Answer AI LLM uses to craft a complete, context-aware response.
-
Rich Interactions & Forms: Output isn’t just a text bubble—ai12z supports branded forms, CTAs, and dynamic UI controls (validation fields, date pickers, sliders, file/image upload, and more), making it easy to collect info and guide users to take action.
-
Continuous Optimization: Built-in analytics, logs, and diagnostics empower you to optimize performance, tune prompts, and ensure the assistant always puts your brand’s best foot forward.
Integrations - Data flow, and Carousels
The Carousel Control in ai12z provides a dynamic, interactive way to present large datasets, without relying on the LLM to render every item in its response. While RAG (Retrieval-Augmented Generation) is excellent for precise, document-based answers, use cases like restaurant menus, product catalogs, and movie listings often involve large result sets that are inefficient to render directly through LLM output.
The limitation is usually not input size. Modern models with large context windows can ingest substantial JSON payloads. The bigger challenge is output generation: long, item-heavy responses increase latency and cost.
A client-side carousel bypasses this bottleneck by sending structured data directly to the Bot UI for rendering. This improves responsiveness and cost efficiency while still allowing optional LLM support for summary, comparison, and contextualization. You can also share data with both the carousel and the LLM, so when results are limited (for example, 0 or 1 item), the LLM can add helpful context. The Carousel integration creates your Handlebars template, JavaScript, and CSS created with Vibe Coding.
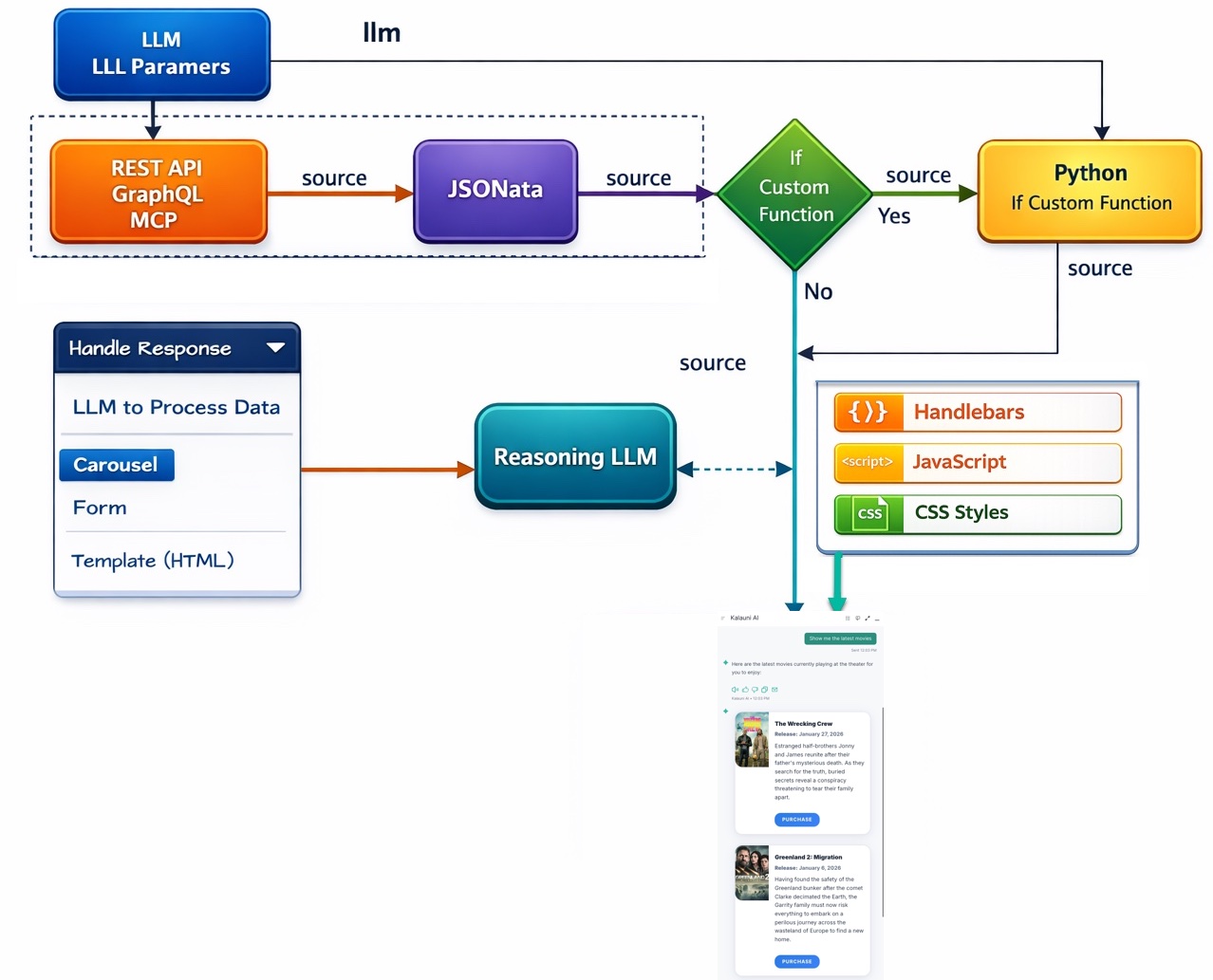
Example cards results of asking about nearest store, ai12z geo location services gets your location, python code sorts the results (python was created with vibe coding), handlebars template renders the cards along with script and style information, all created with vibe coding
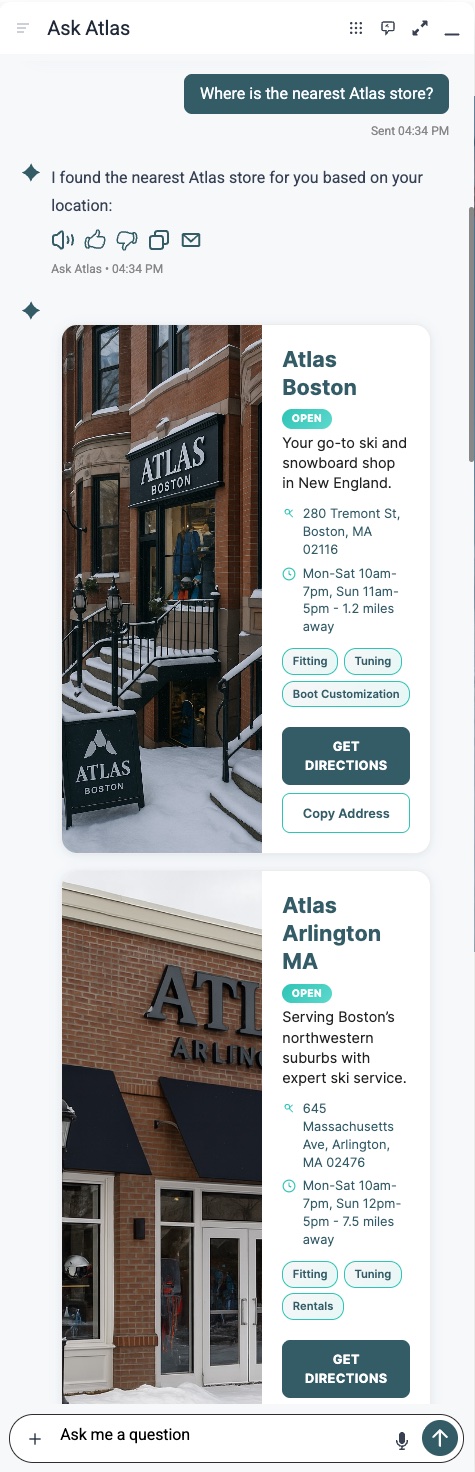
Integrations - Data Flow and Template (HTML)
You can create wizards and advanced calls to action that use third-party APIs. These experiences can be multi-panel, step-by-step workflows. All created using vibe coding
In this example, an endpoint is called to fetch current interest rates. When the user clicks Calculate Payment, the widget returns the calculation and presents calls to action for the next step.
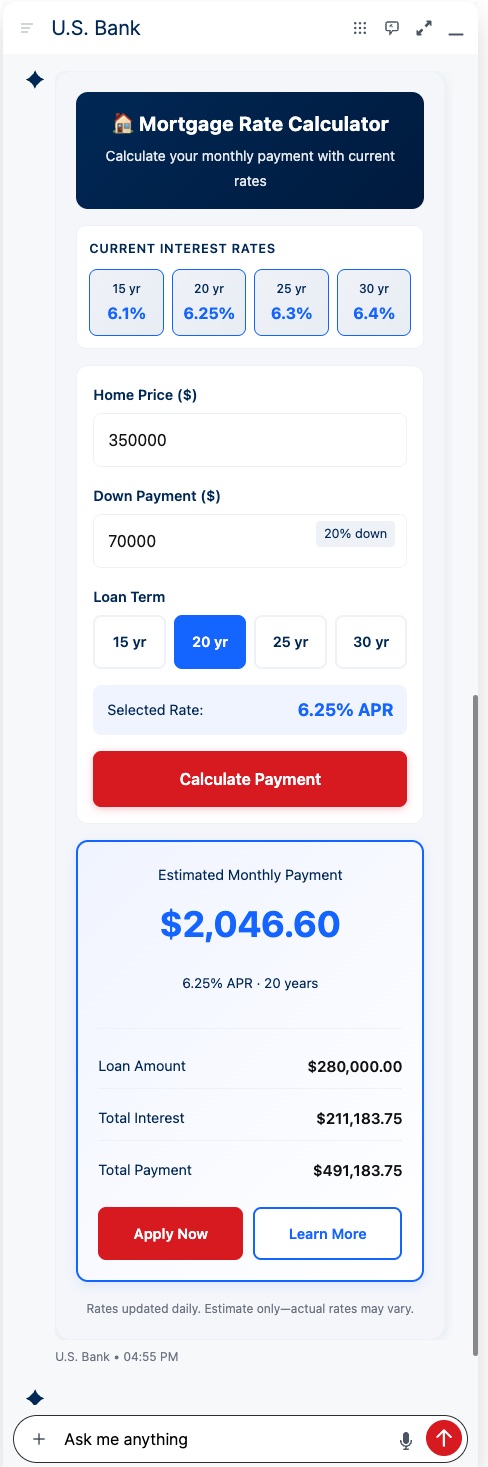
The LLM can also pass parameters into the template. For example, if a user asks for a 20-year term on a $350,000 home price with a 20% down payment, those fields can be prefilled automatically.
Integrations - Input Data and Forms
The ReAct LLM is aware of all enabled forms. ai12z includes an enterprise form builder with Vibe Coding and a drag-and-drop canvas for rapid editing. Fast, structured data collection is essential for digital assistants that need to convert visitors into customers.
Enterprise forms support multi-page flows, validation, and AJAX integrations for real-time checks such as available time slots. This is one of many key differentiators in the ai12z agent builder.
Dynamic System Prompts & Tokens
To maximize relevance, ai12z supports dynamic tokens in prompts, allowing the assistant to reference:
{query}– The latest user question{vector-query}– Context-optimized version of the question{history}– Past conversation threads{language},{geo},{origin}– Key user/session data{attributes}– Custom attributes for deeper personalization, using JS to include Geo info, cookie data, ect..{org_name},{purpose}– For tailoring brand tone and objectives- ...and more including the context of the web page the controls are on
In Summary
ai12z’s ReAct agentic workflow is a step change from yesterday’s chatbots. It orchestrates, reasons, and acts—drawing on your content, your data, and your goals. The result? A branded digital experience that’s as helpful and dynamic as your best team member.
Ready to power up your digital journey? See how ai12z can transform your customer experience—let’s get started!