Website Ingestion
ai12z enables you to ingest entire websites for your AI copilot. This process extracts and indexes web content so your assistant can answer questions based on up-to-date site data.
Start: Open the Website Wizard
From Documents, click Add Document and choose Add Website to open the 3‑step wizard.

Wizard Step 1: Basic Info
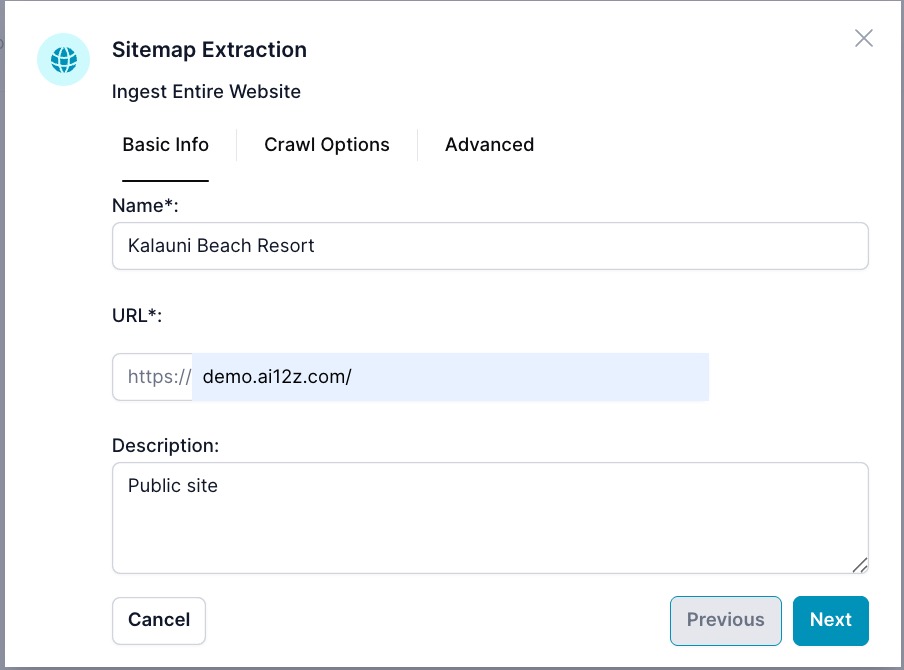
- Name: A recognizable label for this website source.
- URL: The site or section root to ingest (e.g.,
https://www.example.com/). - Description: (Optional) Short note about the site’s content or purpose.
Wizard Step 2: Crawl Options
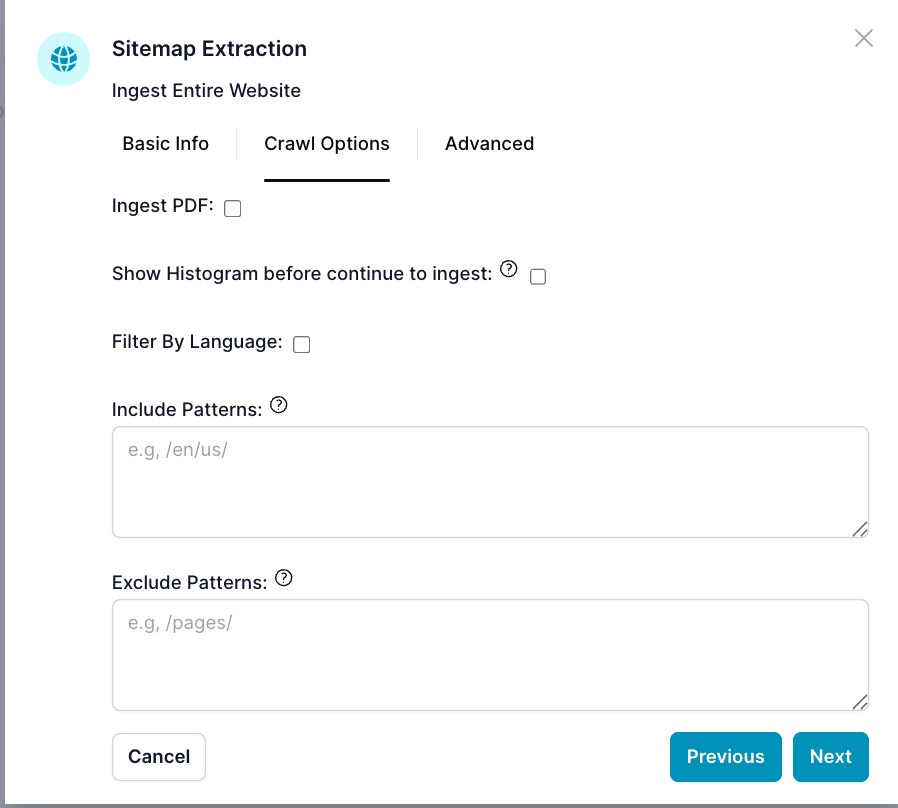
- Ingest PDF: Also process PDFs discovered during crawling.
- Show Histogram before continue to ingest: Preview a URL histogram to review and filter before saving any data.
- Filter By Language: Ingest only pages detected for selected languages.
- Include Patterns: URL substrings to include (one per line, e.g.,
/en/). - Exclude Patterns: URL substrings to exclude (e.g.,
/archive/,/test/).
Wizard Step 3: Advanced
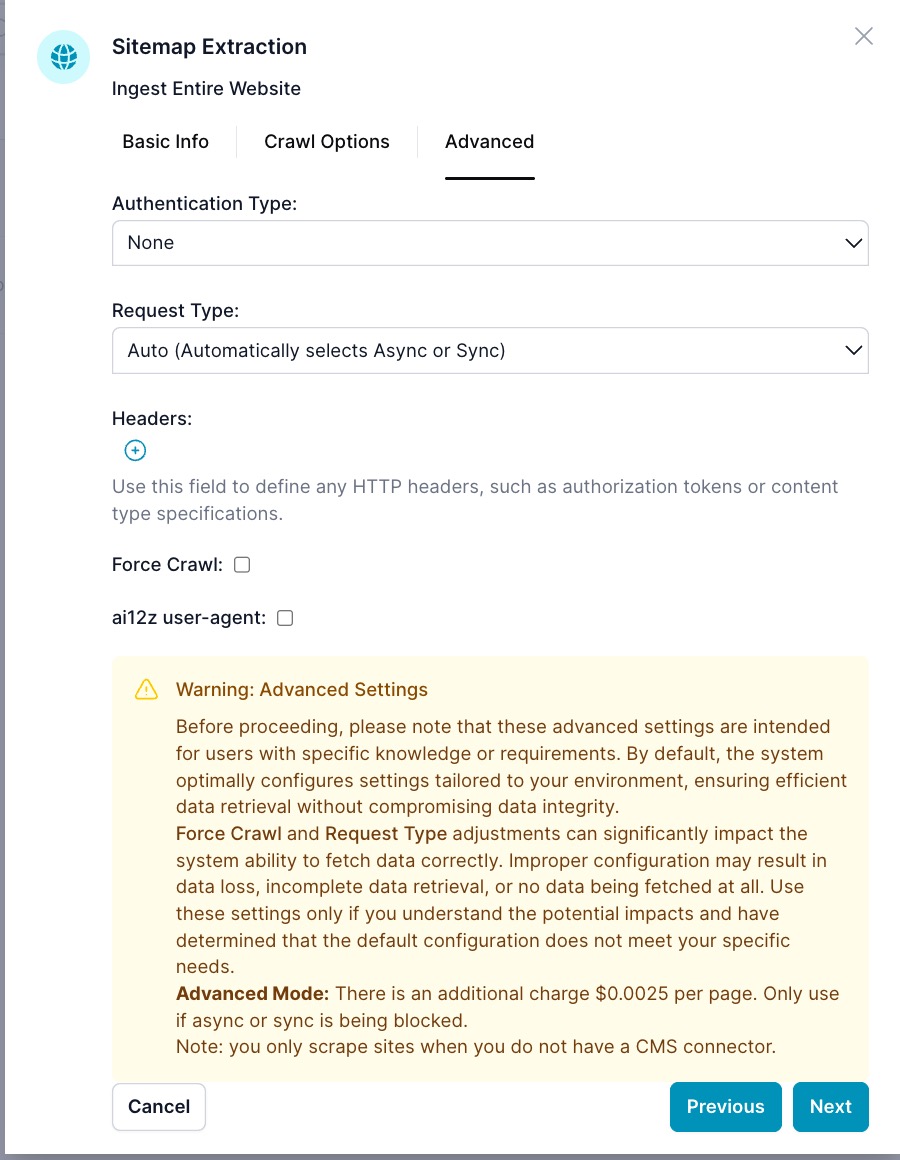
-
Authentication Type:
Nonefor public sites (default).Basicfor username/password.Tokenfor token-based authentication (beta).
-
Request Type:
-
Auto(default): ai12z chooses the best mode for each page. -
Synchronous: Fastest, for traditional sites. -
Asynchronous: Uses a headless browser, for sites that load data with JavaScript. -
Advanced Mode: For sites with extra protection—additional charge per page. -
Headers: Rare to use, sometimes for security
-
-
Force Crawl: Ignore the sitemap and crawl the site. Use when the sitemap is missing, stale, or blocked. Enabling this also bypasses WordPress API ingestion.
-
ai12z user-agent: Identify as
ai12zCopilot/1.0if required by your site. If not checked a common user-agent is used. If the site is behind Cloudflare or similar bot protection, see Whitelisting the ai12z Crawler.
Warning: Adjust advanced settings only if you understand the impact. Non-optimal settings can lead to incomplete or failed ingestions. Advanced Mode incurs an extra $0.0025 per page.
Note: Prefer a CMS connector when available; only scrape sites when you do not have a CMS connector.
What Happens Next: Robots.txt & Sitemap Extraction
-
ai12z checks the
robots.txtfile and sitemaps for allowed paths and crawl delays. -
Progress is shown as the system parses sitemaps and prepares for ingestion.
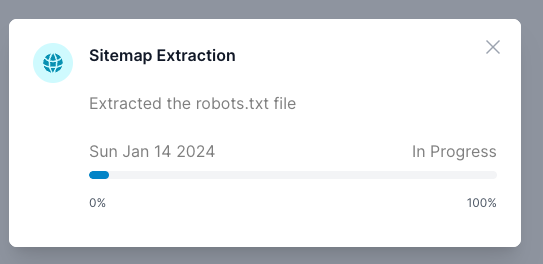
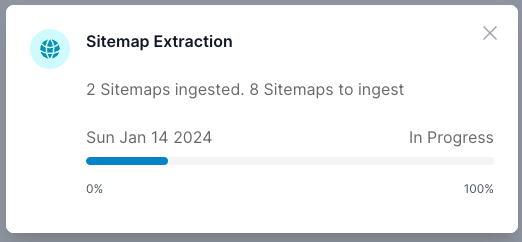
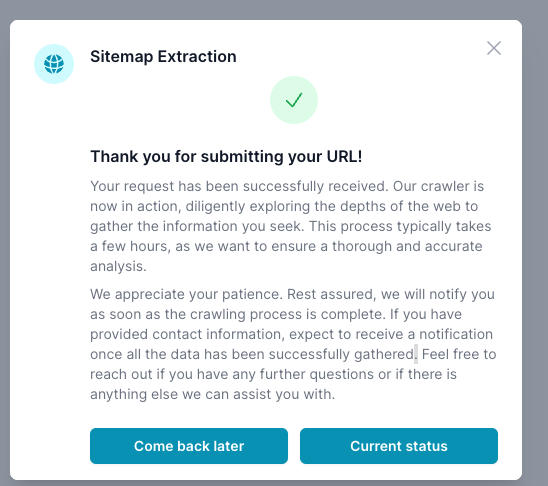
If the process will take a while, you can close your browser or log out. You'll receive an email when it's ready for review.
Optional: Review URL Histogram & Apply Filters
If you enabled “Show Histogram,” you’ll see a breakdown of collected URLs and their counts.
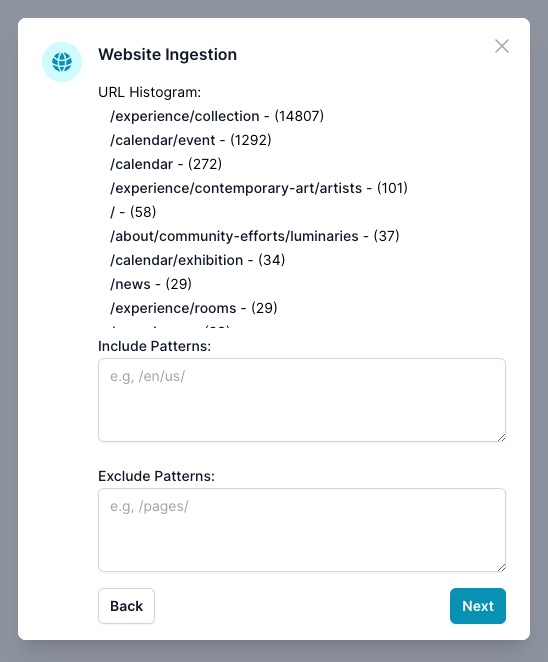
Filtering is optional:
- Include Patterns: Add URL segments (e.g.,
/en/) to restrict ingestion to those paths. - Exclude Patterns: List URL segments to omit (e.g.,
/test/,/fr/). - No wildcards; patterns are matched as substrings to the url.
Finalize and Ingest
- Review your filters and click Next to start ingestion.
- For large sites, ingestion can take hours. ai12z honors
robots.txtcrawl-delay or uses a safe default to avoid impacting site operations. - You'll be notified by email when ingestion is complete.
Monitoring & Managing Ingestion
-
Check Status: From the action menu, select
Statusto view progress orInfofor details. -
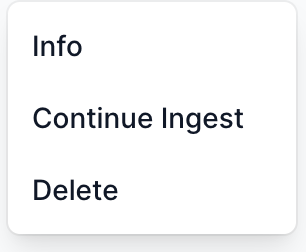
Continue Ingest: If you paused at the histogram step, use
Continue Ingestin the action menu after setting filters.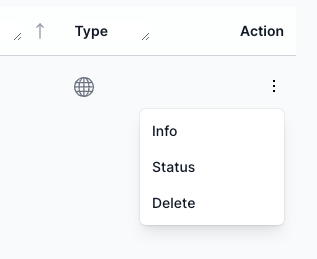
Additional Features
-
Meta Tags: If a page contains
<meta name="tags" content="tag1, tag2">, these tags are added to the vector index for that URL. -
JSON-LD: If JSON-LD is present, it’s ingested with the page content. This can be configured in Agent settings (ingest only JSON-LD or both).
-
If no sitemap is found, ai12z will broadly crawl the site and build a histogram for you to review before data is saved.
Sync
Keep an ingested website up to date by running a one‑time sync or enabling an automated schedule.
Open the Sync dialog
- Open the document Action menu and choose Sync.

The Website Sync Scheduler opens:
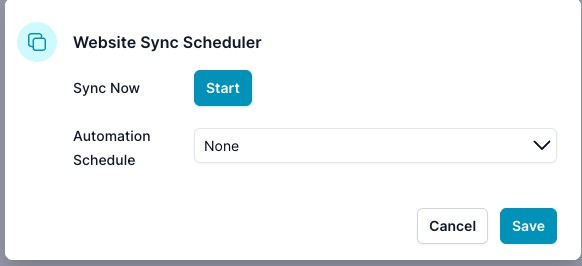
Sync Now (manual)
- Click Start to trigger an immediate sync. This fetches and re-indexes pages that are new or have changed since the last run, respecting robots.txt and your original crawl settings.
Automation Schedule
Choose how often ai12z will sync automatically, then click Save.
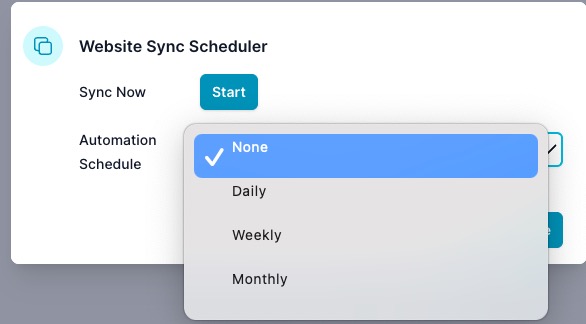
- None: No automatic syncs (manual only).
- Daily: Runs every day at 00:00 (your local time).
- Weekly: Runs weekly at 00:00 (your local time).
- Monthly: Runs monthly at 00:00 on the selected day of the month.
When Monthly is selected, choose the day (1–31):
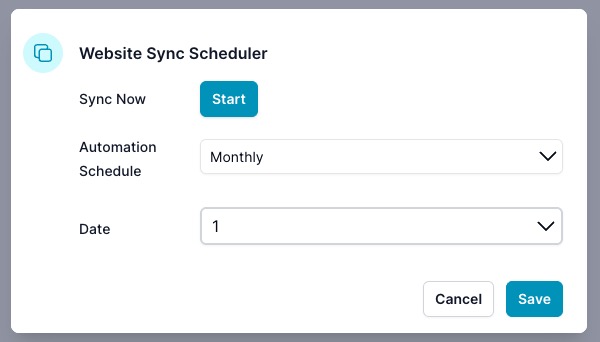
After saving, the dialog shows the active schedule and next run time. Use Modify to change it.
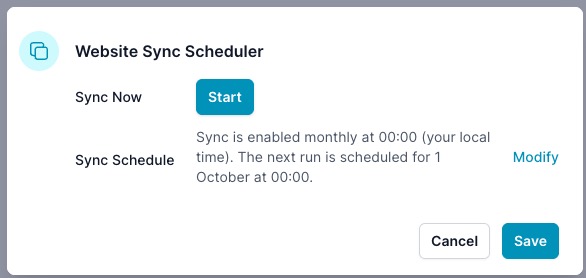
Disable or change
- To disable scheduling, open Sync and set Automation Schedule to None, then Save.
- You can re-open Sync at any time to modify frequency or run a manual Start.
Notes
- Sync respects the same include/exclude patterns and advanced settings you configured during ingestion.
- Large or JavaScript‑heavy sites may take longer. Frequent schedules can increase cost and load—choose the lowest frequency that meets your freshness needs.
- Change detection: we compute a content hash per page and only re‑index pages whose content changed. Embeddings are regenerated only when needed.
- Deletions: if URLs disappear from the site/sitemap, their corresponding vector documents are removed at the end of the sync.
- Availability: your agent stays fully available during sync—there’s no downtime and we don’t re‑ingest from scratch.
- Cost: Website syncs incur a small usage cost. CMS connector syncs are free.
- Sync works with any mode you ingested the web site
Tips & Best Practices
- Use Include/Exclude Patterns to focus on relevant content and skip redundant or irrelevant sections.
- Filtering by language is highly recommended for multilingual sites—preferably include only one language per ingestion run.
- Always check your email (including spam/junk folders) for ingestion notifications from
noreply@ai12z.com.
If you skip “Show Histogram,” the system ingests all discovered URLs immediately. ::
Troubleshooting: Common issues
- Open the document action menu →
Infoto see last errors and counts. - If ingestion hasn’t started, ensure you clicked
Nextafter the histogram (when enabled).
-
JavaScript-rendered pages are empty
- Set Request Type to
Asynchronousor enableAdvanced Mode(Step 3 → Advanced). - Some anti-bot protections may still block; consider a CMS connector if available.
- Set Request Type to
-
Ingested content is garbled, empty, or looks like a challenge/CAPTCHA page
- This usually means the site’s CDN or bot-protection service (Cloudflare, Akamai, AWS WAF, etc.) is blocking the crawler, not a setting on your ingestion job.
- See Whitelisting the ai12z Crawler for the exact IP, user-agent, and header to give the site’s IT/CDN team, plus a ready-to-forward request template.
-
Blocked by robots.txt (Disallow or 403)
- The crawler honors
robots.txt. Whitelist theai12zCopilot/1.0user-agent or the project’s IPs, or ingest via a CMS/API connector. See Whitelisting the ai12z Crawler for the full request to send. Force Crawlignores sitemaps only; it does not bypass robots.txt.
- The crawler honors
-
Sitemap missing or out of date
- Enable
Force Crawl(Advanced) to discover URLs without relying on the sitemap. - Use
Show HistogramandInclude/Exclude Patternsto scope the crawl.
- Enable
-
Pages require authentication or custom headers
- Choose an
Authentication Typeand/or addHeaders(e.g., Authorization). Verify token scope includes all target paths.
- Choose an
-
WordPress content mismatch
- If WordPress API ingestion misses certain content types, enable
Force Crawlto fetch the rendered pages.
- If WordPress API ingestion misses certain content types, enable
-
PDFs not showing up
- Check
Ingest PDFin Crawl Options. Ensure PDF links are reachable and not blocked by robots or auth.
- Check
-
Very large sites take too long or cost too much (Optional)
- Ingest by language or section using
Include Patterns(e.g.,/en/,/docs/). - Run multiple smaller ingests instead of one huge job. Avoid
Advanced Modeunless required (it adds $0.0025/page).
- Ingest by language or section using